In this article

Product updates
Your AI doesn't remember your tracking plan. The Avo MCP does.
Connect your AI agents to your live tracking plan, so it designs and implements analytics that fit your existing data instead of guessing.
Picture this: your product page is getting a quantity selector and a Buy Now button that skips the cart. Your engineer asks their coding agent to design the tracking. It comes back in seconds: a new Buy Now Clicked event, a new Product Quantity property, a Checkout Method property to tell the two purchase paths apart. Confident, clean, ready to ship.
Except all three are wrong. The event: "Clicked" is forbidden as an event action, because names tied to buttons get outdated when the UI changes, and the action isn't even new; Purchase Started already fires for this same checkout flow from the cart page. The property: Item Quantity is already drafted on an open git branch, so that's a duplicate under a different name. The name: Checkout Method sounds like how you're paying for what you're buying, not how you got to the checkout flow, so whoever queries it later will join the wrong column.
The tracking ships anyway. Nobody catches it, because the engineers, like the agent, don't hold the full set of rules and patterns in your tracking plan in their heads.
This is what happens when AI writes analytics blind.
AI writes your analytics confidently wrong
In our companion post, Govern your data. Your agents depend on it., we lay out three beliefs about data in an agent-first world:
- agents are confidently wrong without structured context
- the analytics stack is collapsing onto the warehouse and the agent, which leaves one thing still to govern: what your data means
- governance has to be correct every time, because "it ran" isn't the same as "it's trusted"
Anthropic proved the first one on themselves: Claude went from below 21% to above 95% on their analytics evals without touching the model, just by adding structured context around it. Access to thousands of prior SQL files barely moved the number. Structure did.
Put that Buy Now design next to those evals and you see two failure modes with one cause: at design time, agents invent tracking that doesn't fit the plan; at query time, asked for "checkout conversion", they guess which events count and hand you a confident, wrong number. A better model fixes neither. What fixes both is a structured, live view of what your data means, in the agent's hands before it acts. For analytics, that view has a name: the tracking plan.
The Avo MCP: your tracking plan, in the agent's hands
Avo is where teams design and govern their tracking plan: the live source of truth for what your events mean and how they're used, read by humans and agents alike.
The Avo MCP is the agents' way in: an MCP server that connects Claude, Cursor, ChatGPT, Codex, Gemini, or any MCP-compatible client directly to your plan, imported from whatever you keep it in today. From there, the agent can:
- Search your events, properties, and metrics by meaning, not just by name.
- Design tracking for your next feature, starting from its PRD or Figma, onto an Avo branch (your plan, source-controlled like code) that follows your existing patterns and rules.
- Implement from the code snippets and steps Avo generates from the branch, so what ships matches what was designed.
- Query your product data in your warehouse (BigQuery, Snowflake, Databricks) or analytics platform (Amplitude, Mixpanel, PostHog): your data tool computes the answer, and Avo's metric definitions pin what it means, so "checkout conversion" counts the events your team agreed on, not whichever ones the agent guesses.
Think of it as planning mode for analytics agents: before the agent writes a line of instrumentation code, it consults the tracking plan, the same way you'd check whether a function already exists before writing a new one. In practice: ask "do we already track starting a checkout?" and the agent comes back with Purchase Started and its full schema, even though "checkout" isn't in the name.
And when it writes, everything lands on an Avo branch, never on main, with a diff URL to review in Avo. The agent proposes. You decide what merges. When it answers questions about your data, the same plan grounds the analysis: metrics computed as your team defined them. (For the full set of workflows, see the use cases in the docs.)
This isn't just a faster version of the old process; it reverses the order. Governance moves from cleanup at the end to the first thing the agent reads. That reversal is the real step into the agent era.
A static schema is stale the moment it's saved
Anthropic's published playbook for agent analytics puts governance in the semantic layer: metric definitions the agent can't drift from. That works for querying. But by the time data reaches the semantic layer, the events beneath were already designed, named, and instrumented upstream, and that's where correctness is decided. Govern only at the bottom, and every layer above is policing decisions already made: the deferred-source-of-truth problem our companion post names.
The tracking plan is where those decisions happen. And it's mostly lived in static documents: a spec in Notion, a schema in a Google Sheet, a JSON Schema or YAML file in a repo. That was fine when only humans were writing the tracking calls. Now agents write them too, and an agent mid-task needs three things a sheet doesn't hold:
- The rules: a sheet lists names, not the convention behind them, so the agent infers the rules from the rows, drift included.
- Potential conflicts: tracking another team or developer already drafted or implemented, which never made it into the sheet.
- The latest version: a sheet is whatever it looked like when someone last remembered to update it, and any iteration that didn't make it in is the agent's blind spot.
Avo holds all three, and more. The rules are enforced configuration, not a convention to reverse-engineer from names. Conflicts surface before you hit them: another team's draft is a branch in the same plan, visible before you collide with it. The latest version is the plan itself: nothing to fall out of sync, because the plan is where the change happens. Until now, all of that was built for humans to read. The MCP hands that live source of truth to the agent: where a semantic layer governs your data after it ships, this governs each decision before it does. And you don't need the full Avo suite to start; the MCP is useful on its own, from the first search.
The agent era doesn't break data quality. It just requires governance to speak the same language as agents.
We ran the experiment: first blind, then grounded
That Buy Now design above (the blocked event, the duplicate, the misleading name) isn't a thought experiment. It's what an AI agent actually produced when we handed it the quantity-selector-and-Buy-Now feature in a demo workspace built like a real one: a populated e-commerce plan, enforced rules, a stack of open branches. It worked from the requirement doc plus a static export of the plan. Then we ran it again, same agent, same doc, this time in the Avo harness: the MCP reading the live tracking plan, and our tracking skill (a written playbook the agent follows) supplying the method.
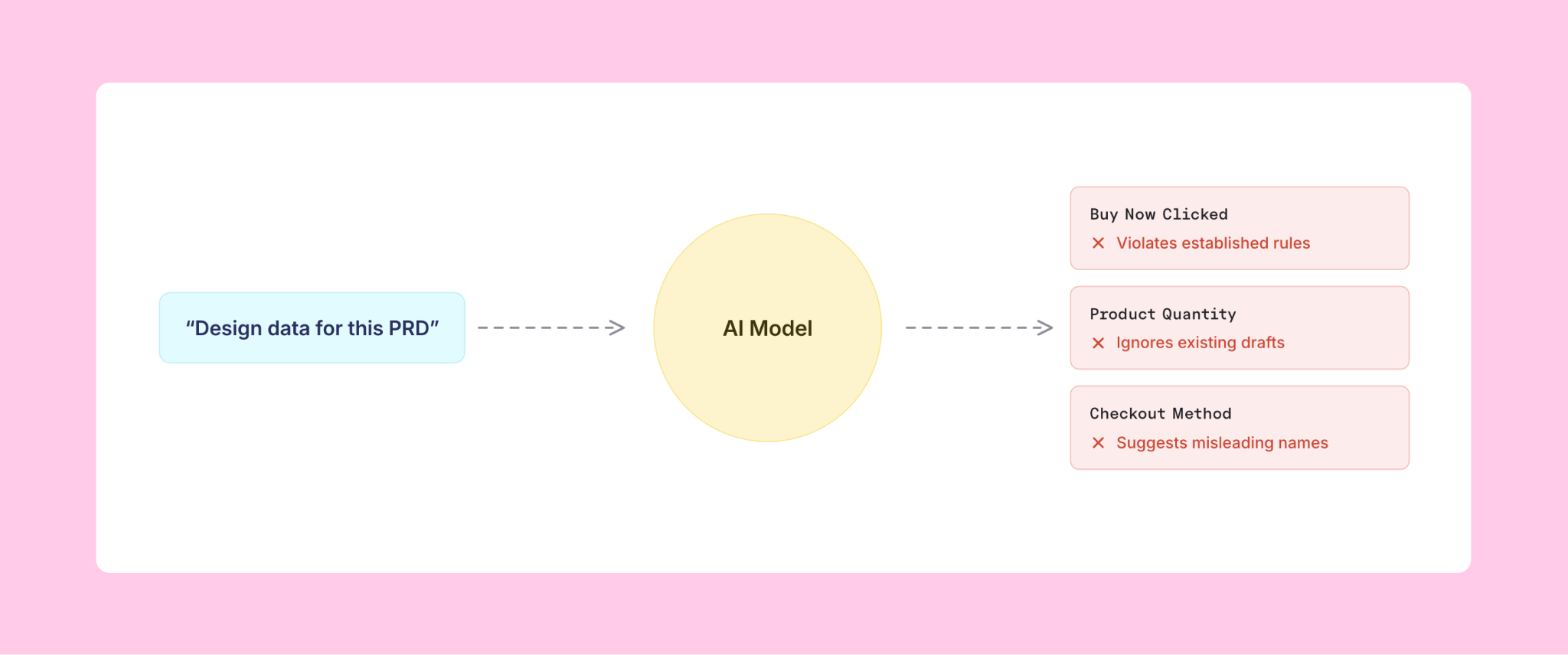
Both runs (with the MCP and without) got the overall shape right: reuse the checkout funnel, model quantity and path as properties, the same metrics, the same data-quality bugs flagged. Everything that touched the real plan flipped:
- The event the rules forbid. The grounded run read the tracking plan's governance rules (enforced at merge) and found "Clicked" blocked. Buy Now starts the checkout flow, which the existing
Purchase Startedevent already models (today it fires from a different button with different copy). Same action, same event: zero new events, and the path became a property. - The duplicate. Instead of minting
Product Quantity, the grounded run adopted theItem Quantitydraft from the open branch, and surfaced the plan'sProduct *versusItem *naming split for the team to resolve. - The misleading name. The path property shipped as
Purchase Flow, notCheckout Method, steering clear of the three* Methodproperties that mean other things (how you pay, how you sign in).
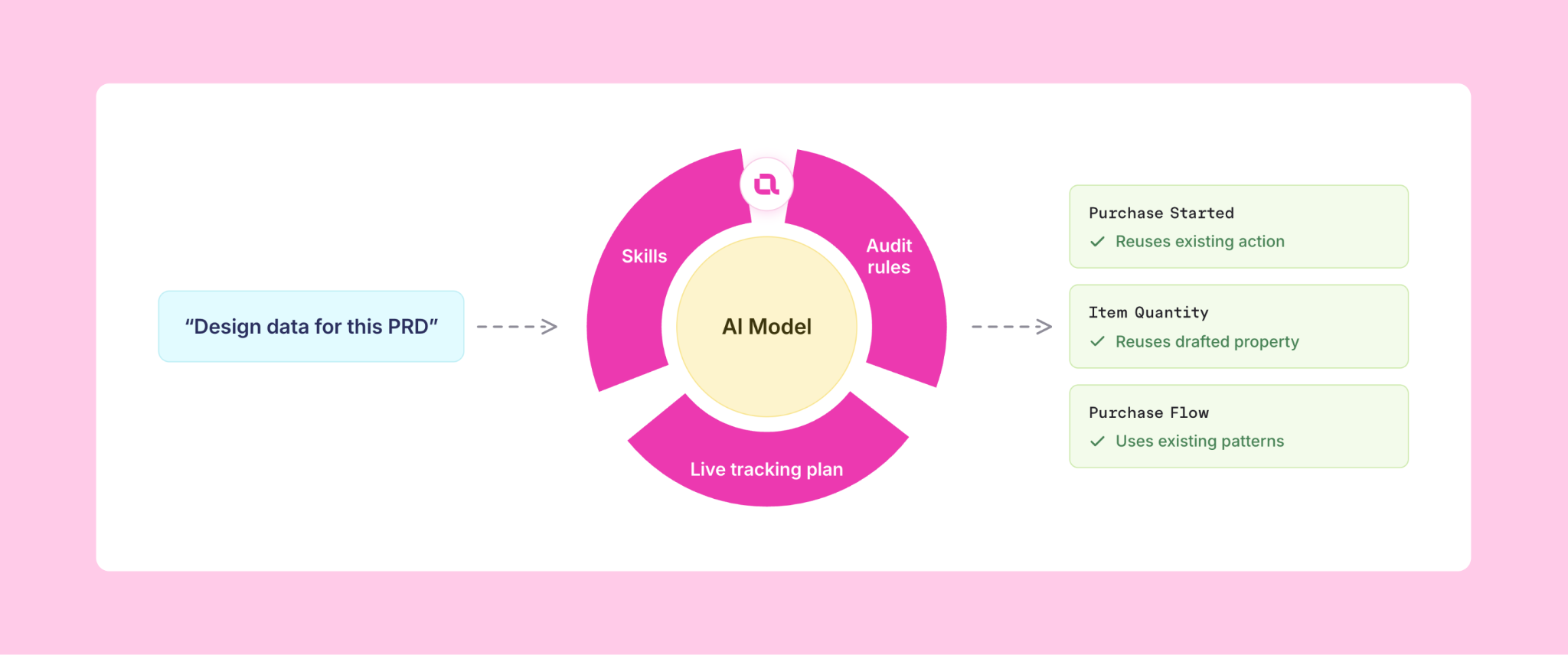
To be fair, the blind design is fast, works offline, and for a brainstorm it's fine. But run the grounded version on your own workspace and it won't surface these three problems. It'll surface yours: the ones hiding in your rules, your open branches, your existing names. An agent working from a snapshot can't see those. It needs the plan itself.
Same model. Different harness.
What's in the harness?
The harness is everything around the model that decides whether it's right: the method it follows, the rules it's held to, and the live tracking plan it can see.
Anthropic built theirs by hand: a skills repo colocated with their data code, maintained by their own data team, CI to keep it honest. It works, for them. And half of it you could build here too: write yourself a tracking skill from a template, hand your agent a snapshot of your tracking plan. The skill half holds up, because good design rules fit in a file. The truth half doesn't: which drafts are open, which rules are enforced, which names are taken changes every day, and a snapshot is stale the moment it's taken. The method is copyable. The truth is not.
The Avo MCP gives you both halves:
- Method. The open-source Avo agent skills carry the tracking-design playbook the grounded run followed; they install as a Claude Code plugin (MCP server included), and we maintain them as the product evolves. On top sit the audit rules you configure in Avo: your own conventions, enforced when a change merges, like the one that blocks "Clicked".
- Truth. The plan is that live source of truth, source-controlled like your code, so the agent sees the
Item Quantitydraft on its open branch and every name already taken, the things no static file can know.
Skills teach the agent how to design. Your audit rules hold it to your conventions. The MCP tells it what's true right now. The branch workflow decides what ships; Avo's typed codegen and the Inspector, watching production, catch drift between the plan and what actually runs. The only part left for you to write is the prompt.
What's next for the Avo MCP
The MCP has been in beta for a while. Today we're launching it officially, one step on a path we're already building: the agent-first workflow, where agents design, implement, and verify tracking end to end, and pull a human in when they're not confident or when your governance rules require it, like a stakeholder review on PII changes.
There's more coming: an agent inside the Avo UI, plus journeys (where in your product each event fires) and review workflows through the MCP. The principle stays: agents do the work, humans decide what ships.
Get started
The Avo MCP is available now. Add the server (https://mcp.avo.app/mcp) to Claude, Cursor, ChatGPT, Codex, or Gemini and authenticate with your Avo account. The setup docs cover every client. New to Avo? Create a workspace at avo.app first; it's free, and you can import the plan you already have.
Then start with a question: ask your AI assistant what's already in your tracking plan, or whether an event for your next feature exists. You'll have an answer in seconds, and your AI will have the context to propose tracking that fits the plan, whether that plan is years old or created this morning.
Block Quote

